AI影音模型库创建系统
一站式智能创作解决方案,赋能高效安全内容生产
AI影音模型库创建系统依托自主研发发明专利,集成语音克隆、数字人分身、多模态内容生成与影音合成等核心技术,以“碎片化生产、分段式组合、模块化拼装”的创新模式,结合本地化部署优势,为政府、教育、企业及各行业内容创作者提供高效、稳定、安全的全流程智能创作工具。无需专业技术基础,即可快速生成高仿真素材与内容,显著缩短制作周期、大幅降低创作成本,全方位满足教学课件、企业宣传、产品演示、自媒体内容等多样化生产需求。

功能模块:构建全流程智能创作闭环
语音克隆:打造多语种专属声音库
支持“极速复刻”与“音色训练”两种模式,覆盖音色导入、创建、编辑、检索全环节,助力用户快速搭建独享声音库。
高效复刻:仅需提供3-10秒音频,即可快速生成专属音色;若追求更高精度,1分钟内原声录制即可完成音色微调,全程自动化处理,总耗时不超过10分钟。
多场景适配:生成的AI语音模型可长期保存、反复调用,支持中文(含粤语)、英文、日文、韩文等语言输出,能灵活调节语速,同步生成带字幕的音频文件,适配配音、播报、讲解等多样需求。
低门槛创作:内置4种无版权争议的基础声音模型库,无需额外训练即可直接调用,降低创作启动成本。

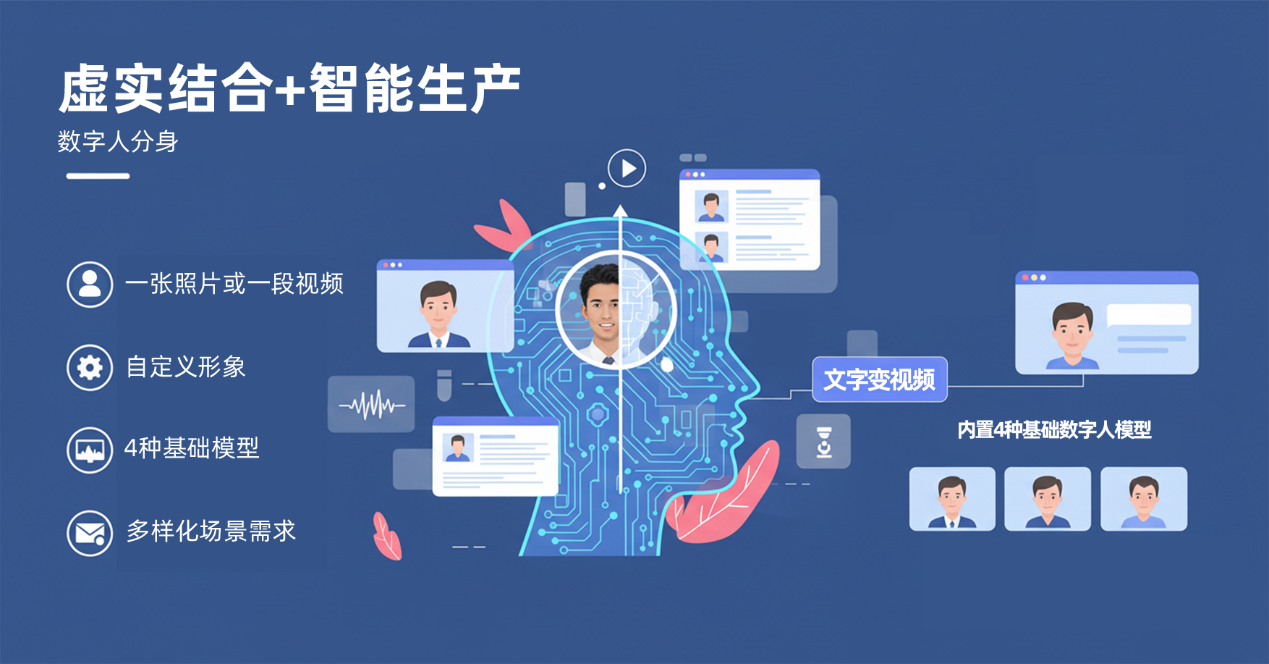
数字人分身:高效完成智能化内容生产
无需复杂操作,轻松生成高仿真数字人形象,虚实结合,满足多样化场景需求。
便捷生成:用户上传一张照片或一段视频,AI可自动生成高度仿真的数字人分身;也支持自主上传自定义形象,满足个性化需求。
智能驱动:通过简单文字输入,即可驱动数字人实现口型同步的视频播报,支持标准、可爱、夸张等多种嘴型风格调节,可自定义人脸比例并叠加字幕,真正实现“文字变视频”的高效转化。
即开即用:内置4种无版权争议的基础数字人模型库,开箱即可投入使用,助力快速开启安全教育、知识科普、企业形象展示、自媒体创作等系列视频制作。
一键换装:超全虚拟服装库降本提效
全新升级的个人虚拟服装库模块,全面革新数字人形象塑造方式。
丰富风格:涵盖日常办公、节日主题、商务交流、民族特色、活动宣传等多种风格的服装,用户可按需自由搭配,满足不同场景的形象需求。
成本优化:无需购置、租赁实体服装,大幅节约置装与存储成本;同时省去服装搭配和场景适配的时间,提升创作效率。
形象统一:在内容升级迭代时,能保持数字形象的连贯性,增强内容资源的辨识度,适用于企业宣传、个人IP打造、系列内容创作等需要固定形象输出的场景。

影音合成:多素材融合+全流程编辑
提供从素材处理到成品导出的全流程服务,保障高清输出与多场景适配。
多素材兼容:支持视频、图片、PPT等多类型背景与前景融合,导入素材后可借助智能抠图技术分离前景人物或图像,完成色度键控、平滑边缘处理等精细化操作。
全能编辑:具备音视频剪辑、多素材叠加融合、图文配音、封面帧设置等功能,在保障高清画质的同时兼顾高效存储,避免占用过多设备空间。
精准输出:导出视频支持字幕烧录,实现音、画、字精准同步,兼容主流播放器,可满足教学课件、企业培训视频、产品宣传视频、自媒体内容等各类成品输出需求。

核心优势:赋能高效安全生产
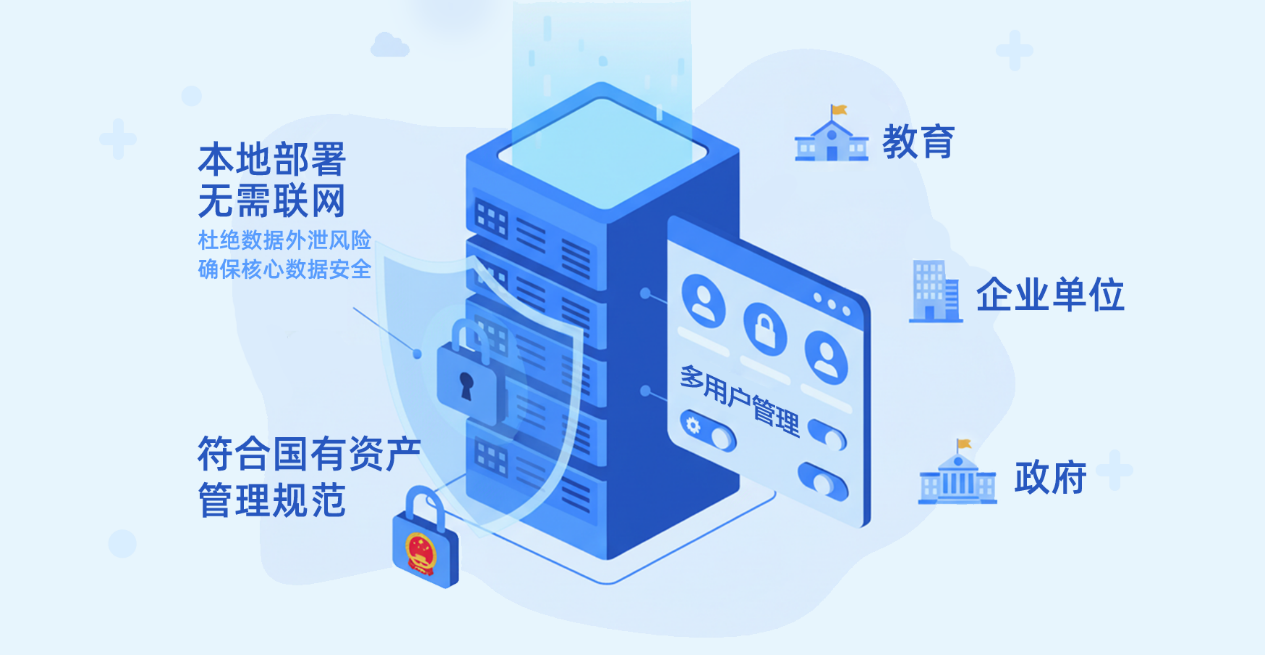
本地部署:牢筑数据安全屏障
支持本地化部署与离线使用,所有AI运算均在本地完成,无需联网即可操作,从根源杜绝数据外泄风险;符合国有资产管理规范与通用资产管理标准,采用多用户管理模式,管理员可统一配置用户账号、AI模型状态及系统参数,每个用户数据独立存储,确保核心数据与系统资产归属清晰、可控,为政府、教育、企业等对数据安全有高要求的单位提供可靠保障。
透明定价:无付费陷阱成本可控
秉持透明化定价原则,用户一次购买即可获得系统完整功能使用权,享受终生无限制使用权益,不存在模块解锁、授权续费、功能订阅等二次付费陷阱。清晰的成本结构让用户无需担忧额外开支,可专注于内容创作,有效降低长期使用成本,减轻个人及企业的运营负担。

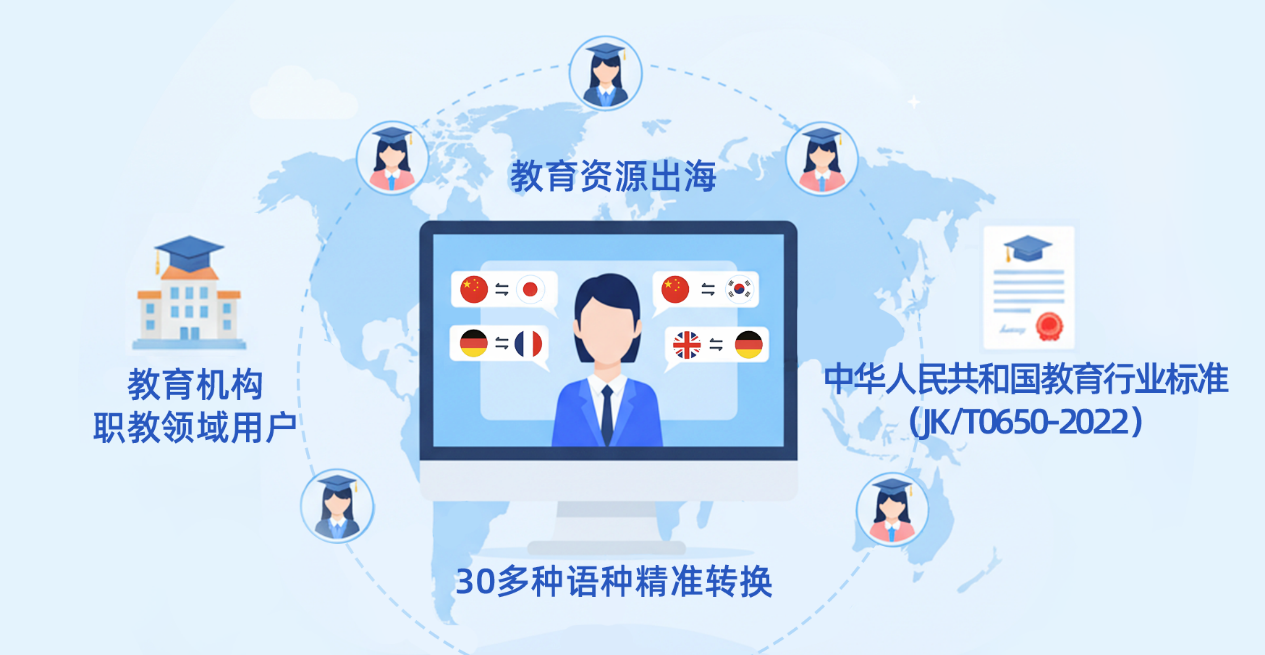
多语种赋能:助力指教出海与全球化
依托强大的多语言处理能力,在语音合成与数字人播报环节,可实现30多种语种精准转换与输出,重点覆盖东南亚及其他热门区域小语种。
对教育机构及职教领域用户而言,能快速将课程内容转化为多语言版本的数字人教学视频,契合中华人民共和国教育行业标准(JK/T0650-2022)中数字教育资源传播要求,助力优质教育资源突破语言壁垒,高效出海。
对企业用户而言,可将产品宣传、品牌介绍等内容转化为多语言版本,辐射全球不同地区,契合跨区域交流、国际业务拓展、全球化内容传播等战略需求。
综上,无论是政府单位制作政策宣传物料、教育机构开发教学课件与实现职教出海、企业打造产品宣传视频与虚拟主播,还是个人创作者产出自媒体内容与知识科普系列视频,系统均能凭借“一站式”智能创作能力,大幅提升内容生产效率、降低人力与物资成本,成为各行业智能化内容生产的理想选择。